
Abstract
CutMix has become the de facto standard mixing augmentation, yet its label assignment rests on a flawed assumption: The area of the pasted patch faithfully reflects its semantic contribution to the mixed image. In practice, however, patches frequently land on background regions, assigning label credit to classes whose objects are not visible. The mean discrepancy of the CutMix label and the semantic object area is 21.5%. In 17% of samples an image contributes zero visible object pixels yet receives nonzero label weight. We propose Object-Aware CutMix (OA-CutMix), which corrects this bias by replacing the area-based CutMix weight with one derived from precomputed segmentation masks, assigning labels in proportion to the visible object area each image contributes to the mix. The image mixing procedure is left entirely unchanged. We evaluate OA-CutMix against 10+ static and dynamic mixing methods across 4 architectures and 6 datasets. OA-CutMix consistently achieves the highest accuracy over all tasks, outperforming even dynamic mixing methods, but at a fraction of the training-time cost. Improvements are largest for small objects, where the label bias from CutMix is greatest. Thus, correcting the label is sufficient to match or exceed the performance of methods modifying the image mixing algorithm.
The Problem: CutMix Labels Lie
CutMix builds a training sample by cutting a rectangular patch ($x_1$ to $x_2$ by $y_1$ to $y_2$) from one image and pasting it onto another. The mixed label is set proportionally to the patch area:
$$\tilde{y} = \lambda_{\text{CutMix}} \cdot y_A + (1 - \lambda_{\text{CutMix}}) \cdot y_B, \qquad \lambda_{\text{CutMix}} = 1 - \tfrac{(x_2-x_1)(y_2-y_1)}{HW}$$The premise is that patch area is a good proxy for semantic contribution. It is not:
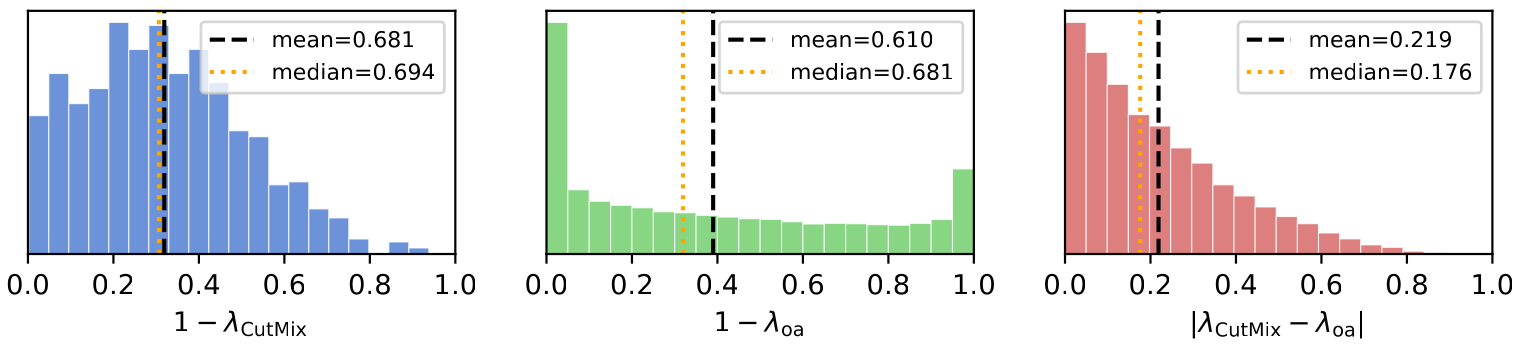 CutMix labels cluster around their expected value, while the true object-aligned label has far more mass near 0 and 1. Most mixed images are dominated by a single object. The two disagree by 21.5% on average, correlate only moderately (r = 0.587), and CutMix systematically overestimates the pasted patch’s contribution.
CutMix labels cluster around their expected value, while the true object-aligned label has far more mass near 0 and 1. Most mixed images are dominated by a single object. The two disagree by 21.5% on average, correlate only moderately (r = 0.587), and CutMix systematically overestimates the pasted patch’s contribution.
Ghost labels
The most damaging case is the ghost label: the patch contributes no object pixels at all, yet CutMix still assigns nonzero weight to that class — the model is asked to predict a class with zero visual evidence.
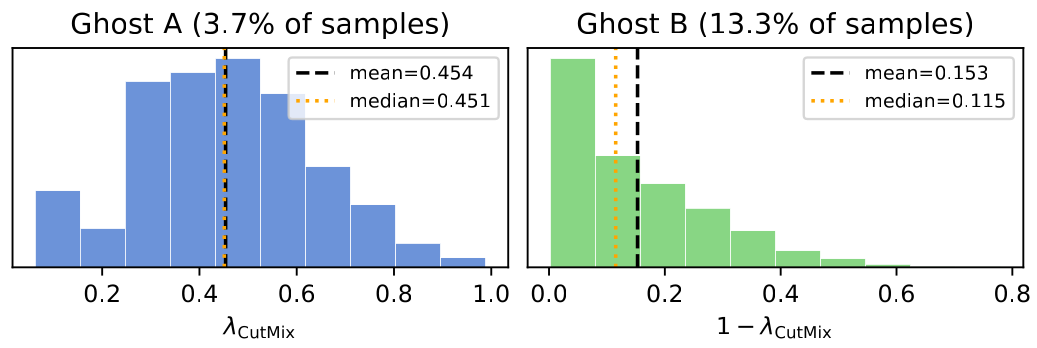
These samples are not merely imprecise. They are categorically wrong.
How OA-CutMix works
OA-CutMix is a drop-in label fix with two parts: offline mask generation and online label reweighting. The mixed image is identical to CutMix.
Offline — mask generation
We segment each training image once with SAM3, prompting it with “a <class name>, <hypernym>” (hypernyms from WordNet for ImageNet-based sets, the coarse category for CIFAR, the global object type for fine-grained sets). An adaptive threshold
keeps confident detections strict and rescues weak ones down to 0.01. On ImageNet, 80.9% of images yield a confident detection and only 1.6% yield none. Masks are stored and loaded alongside images.
Online — label reweighting
Masks travel through the augmentation pipeline with their images, so spatial alignment is preserved. After mixing, we count the visible object pixels each image contributes and set the label weight accordingly:
$$\lambda_{\text{oa}} = \frac{f_A}{f_A + f_B}$$Two variants: /abs counts raw visible object pixels, /rel normalizes by each object’s full size so small and large objects count equally. If neither image has a mask, /rel falls back exactly to standard CutMix. By construction, a patch with no object pixels gets weight 0 and thus ghost labels are eliminated.
Compute Cost
Generating masks for all of TinyImageNet takes 152.1 min on a single H100 (657.4 img/s) — less than a single CutMix training run (223.1 min) — and is reused across every experiment. At train time, mixing runs at ~1.0 ms/batch, on par with CutMix and more than 10× faster than dynamic methods.
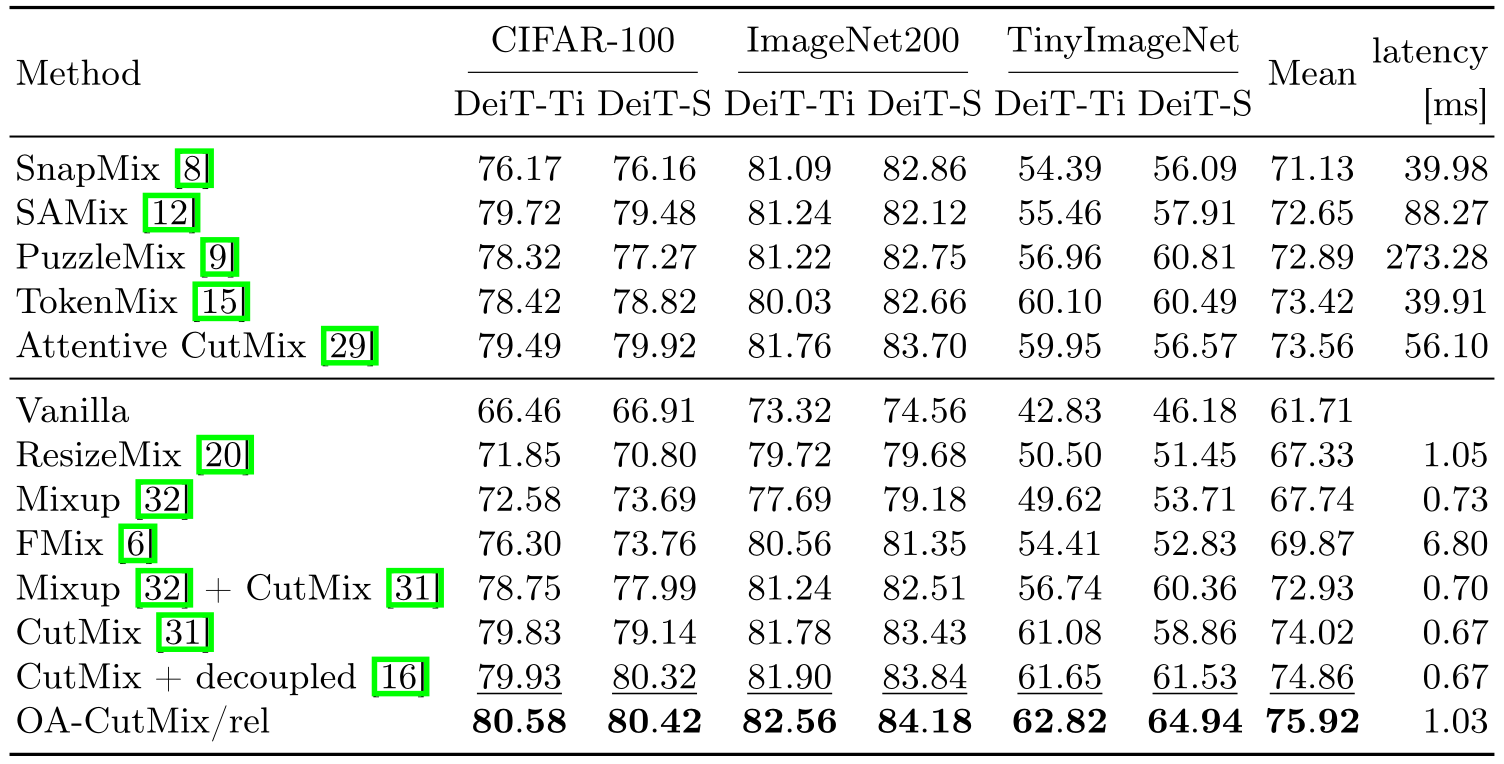
Results
Training from scratch. For DeiT, OA-CutMix/rel achieves the highest accuracy in all six settings, beating both static and dynamic methods while matching the latency of static mixing. For ResNet, it attains the best mean accuracy overall; PuzzleMix is a close second — but at 300× the train-time cost.
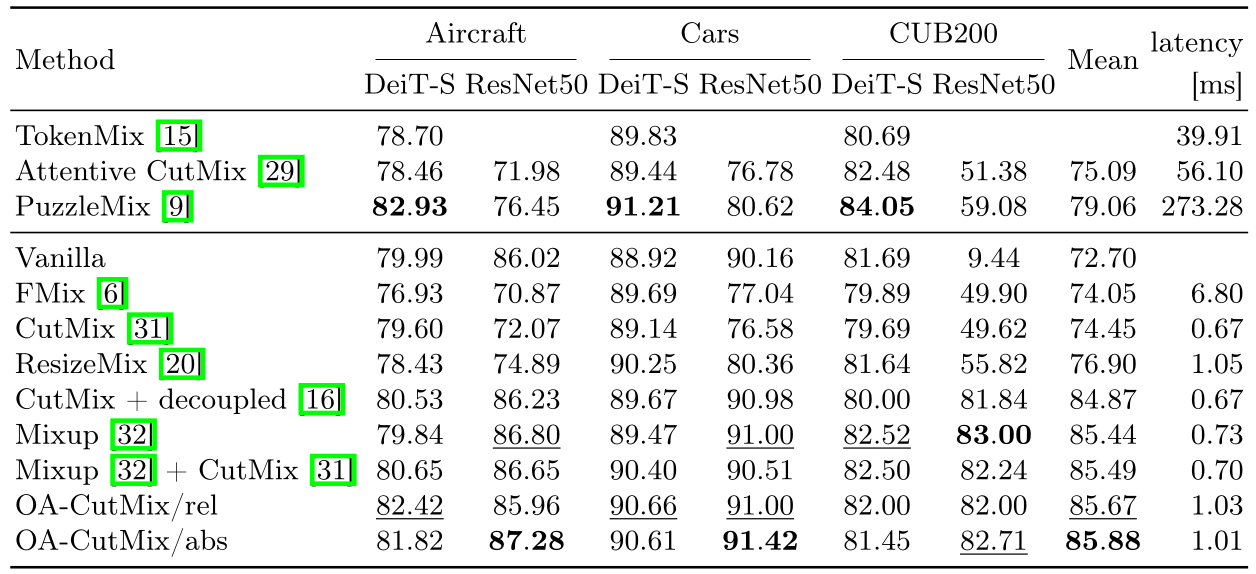
Finetuning (fine-grained). Across FGVC-Aircraft, Stanford Cars, and CUB-200, OA-CutMix reaches the highest mean accuracy, with its four variants occupying the top positions; /abs leads on ResNet50.
Calibration. Because the soft labels are more semantically accurate, the models are better calibrated too. OA-CutMix is the only method to reach sub-5% mean ECE, improving CutMix from 9.08 → 4.27 (ResNet) and 8.75 → 3.27 (DeiT) — and beating the dynamic methods on calibration as well.
Why it works: object size
If the mechanism is really label correction, the gains should concentrate where CutMix’s label error is largest: on small objects. They do.
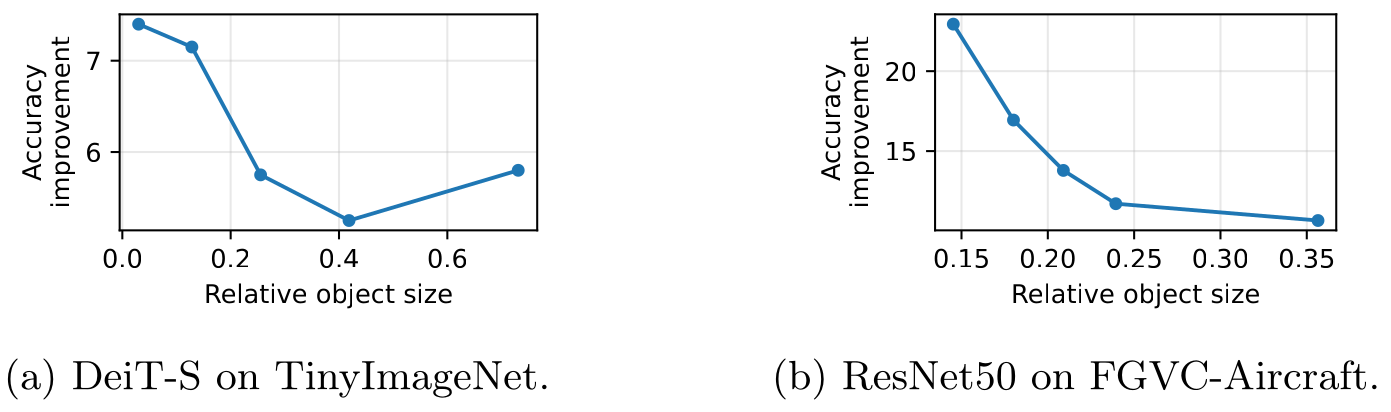 Per-bin accuracy improvement of OA-CutMix over CutMix vs. object size. The gain is largest for small objects, exactly mirroring the misalignment profile of the label error. Large objects fill the frame, area and object coverage converge, and the two labels agree.
Per-bin accuracy improvement of OA-CutMix over CutMix vs. object size. The gain is largest for small objects, exactly mirroring the misalignment profile of the label error. Large objects fill the frame, area and object coverage converge, and the two labels agree.
Ablation: how good do the masks need to be?
We progressively degrade the masks to isolate what matters:
- Replacing SAM3 masks with bounding boxes (position kept, shape discarded) still recovers roughly two thirds of the gain — position alone is already informative.
- Shuffling masks within and then across classes degrades accuracy monotonically — confirming the labels track the correct image, not just class statistics.
- Notably, SAM3 masks outperform the human annotations shipped with CUB-200, which are coarser than SAM3’s output.
OA-CutMix is therefore robust to imperfect segmentation, and benefits monotonically from better masks.
Contributions
- A systematic analysis of CutMix label bias, quantifying its dependence on object size and the ghost label phenomenon.
- OA-CutMix, a foreground-aware label reweighting strategy from SAM3 masks, requiring no change to the image mixing and no training-time overhead.
- A comprehensive evaluation against 10+ mixing methods across 4 architectures and 6 datasets, supporting the hypothesis that label correction alone recovers the gains of slower dynamic mixing.
Citation
If you use this work, please cite our paper:
@misc{nauen2026oacutmix,
title = {OA-CutMix: Correcting the Label Bias of CutMix},
author = {Tobias Christian Nauen and Stanislav Frolov and Federico Raue and
Brian B. Moser and Andreas Dengel},
year = {2026},
eprint = {2606.04820},
archivePrefix = {arXiv},
primaryClass = {cs.CV},
}
