Abstract
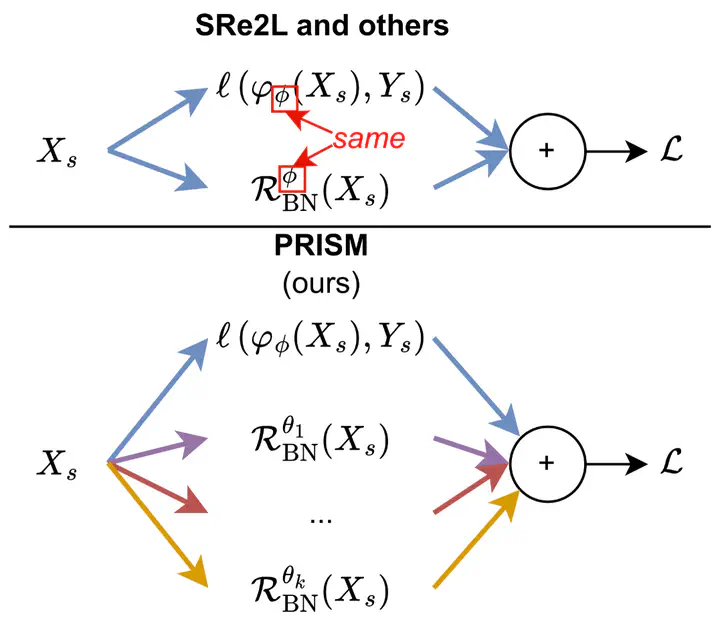
Dataset distillation (DD) promises compact yet faithful synthetic data, but existing approaches often inherit the inductive bias of a single teacher model. As dataset size increases, this bias drives generation toward overly smooth, homogeneous samples, reducing intra-class diversity and limiting generalization. We present PRISM (PRIors from diverse Source Models), a framework that disentangles architectural priors during synthesis. PRISM decouples the logit-matching and regularization objectives, supervising them with different teacher architectures: a primary model for logits and a stochastic subset for batch-normalization (BN) alignment. On ImageNet-1K, PRISM consistently and reproducibly outperforms single-teacher methods (e.g., SRe2L) and recent multi-teacher variants (e.g., G-VBSM) at low- and mid-IPC regimes. The generated data also show significantly richer intra-class diversity, as reflected by a notable drop in cosine similarity between features. We further analyze teacher selection strategies (pre- vs. intra-distillation) and introduce a scalable cross-class batch formation scheme for fast parallel synthesis. Code will be released after the review period.
Citation
If you use this information, method or the associated code, please cite our paper:
@misc{moser2025prism,
title = {PRISM: Diversifying Dataset Distillation by Decoupling Architectural
Priors},
author = {Brian B. Moser and Shalini Sarode and Federico Raue and Stanislav
Frolov and Krzysztof Adamkiewicz and Arundhati Shanbhag and Joachim
Folz and Tobias C. Nauen and Andreas Dengel},
year = {2025},
eprint = {2511.09905},
archivePrefix = {arXiv},
primaryClass = {cs.LG},
url = {https://arxiv.org/abs/2511.09905},
}
Tobias Christian Nauen
PhD Student
My research interests include efficiency of machine learning models, multimodal learning, and transformer models.