Abstract
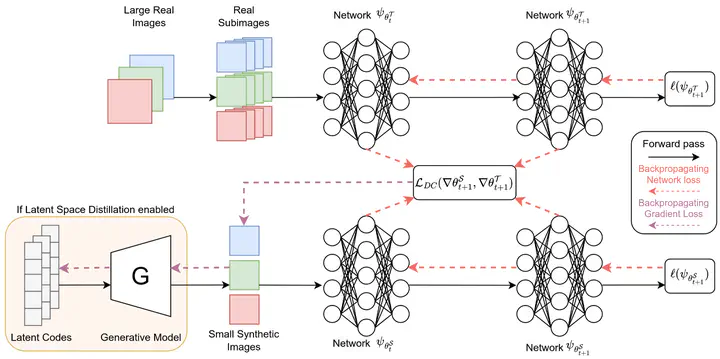
Dataset distillation aims to compress large datasets into compact yet highly informative subsets that preserve the training behavior of the original data. While this concept has gained traction in classification, its potential for image Super-Resolution (SR) remains largely untapped. In this work, we conduct the first systematic study of dataset distillation for SR, evaluating both pixel- and latent-space formulations. We show that a distilled dataset, occupying only 8.88% of the original size, can train SR models that retain nearly the same reconstruction fidelity as those trained on full datasets. Furthermore, we analyze how initialization strategies and distillation objectives affect efficiency, convergence, and visual quality. Our findings highlight the feasibility of SR dataset distillation and establish foundational insights for memory- and compute-efficient generative restoration models.
Citation
If you use this information, method or the associated code, please cite our paper:
@misc{dietz2025datadistillsr,
title={A Study in Dataset Distillation for Image Super-Resolution},
author={Tobias Dietz and Brian B. Moser and Tobias Nauen and Federico Raue and Stanislav Frolov and Andreas Dengel},
year={2025},
eprint={2502.03656},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2502.03656},
}
Tobias Christian Nauen
PhD Student
My research interests include efficiency of machine learning models, multimodal learning, and transformer models.